El fin de la era “Up/Down”
Hubo un tiempo donde alcanzaba con saber si el servidor estaba prendido o apagado. Pero esa era murió. Hoy, la complejidad de los sistemas distribuidos hizo que el monitoreo tradicional se quede corto, tener métricas aisladas es el piso, no el techo.
En entornos que crecen constantemente, necesitamos evolucionar hacia sistemas que nos den respuestas claras. La clave está en lograr que ante lo inesperado el sistema sea capaz de decirnos exactamente cuándo falló, dónde y por qué, permitiéndonos reaccionar antes de que el impacto llegue al usuario.
La observabilidad no es una herramienta que se compra ni un plugin que instalás para que el log se vea con colores en la consola. Es una propiedad de la arquitectura que nos permite interrogar al sistema sobre estados que nunca previmos, yendo mucho más allá de una simple alerta de “CPU al 90%”.
Monitoreo vs Observabilidad
Es común confundir estos términos, pero la distinción es clara:
- Monitoreo (El “Qué”): Se centra en los síntomas. Es el conjunto de métricas y alertas configurables que nos avisan cuando un umbral predefinido se rompe. Nos dice que el sistema tiene fiebre, pero no nos dice la causa. Es reactivo por naturaleza.
- Observabilidad (El “Por qué”): Se centra en el estado interno. A través de la correlación de los tres pilares (logs estructurados, métricas y trazas), nos permite navegar la información disponible para encontrar el origen de un comportamiento anómalo, incluso si es la primera vez que ocurre.
Impacto en la operación y el negocio
Implementar una estrategia sólida de observabilidad y monitoreo no es un “lujo” técnico, es una inversión que impacta directamente en la eficiencia del equipo y en la rentabilidad del producto. Estos son los problemas concretos que logramos mitigar:
- Reducción drástica del MTTR (Mean Time To Recovery): Sin observabilidad, ante un fallo en producción el equipo pierde horas tratando de adivinar el origen del problema. Al tener trazabilidad completa, pasamos de la suposición al diagnóstico basado en datos en cuestión de minutos. Esto nos ahorra cientos de horas de trabajo y minimiza el impacto en el usuario final.
- Detección de fallas antes que el cliente: El monitoreo tradicional nos avisa cuando algo se cae, pero la observabilidad nos muestra cuando algo está funcionando mal (ejemplo: un P95 de latencia que se dispara aunque el promedio parezca normal). Esto nos permite intervenir proactivamente antes de que los usuarios reporten problemas.
- Validación objetiva de deploys y features: Elimina la incertidumbre técnica tras un lanzamiento. Al monitorear flujos internos en tiempo real, podemos validar si una nueva funcionalidad se comporta como esperamos bajo carga real. Si algo sale mal, lo detectamos al instante, permitiendo un rollback seguro o un hotfix preciso, evitando regresiones costosas.
- Eliminación del sesgo en la toma de decisiones: Un sistema observable permite que las discusiones sobre escalabilidad o cambios arquitectónicos dejen de ser opiniones subjetivas. Contar con métricas históricas y correlación de eventos permite al negocio planificar el crecimiento sobre una base sólida de datos reales.
La tríada de datos y las señales de oro
Para que la observabilidad sea efectiva, no basta con recolectar datos, hay que saber qué mirar y donde mirar. Nos apoyamos en tres pilares:
- Métricas: Son datos agregados que nos dan la salud general. Aquí es donde monitoreamos las señales de oro: ¿Cuánta latencia tiene el P99? ¿Cuál es la tasa de error por segundo? ¿Qué tan saturada está la memoria del pod?
- Logs estructurados: Son los registros detallados de eventos. Un log con contexto y enriquecido de buena información nos permite entender el “porqué” de un fallo específico.
- Traces: Nos permite seguir una petición a través de toda la infraestructura, identificando cuellos de botella en el camino de la solicitud.
La magia ocurre cuando estos tres pilares se hablan entre sí. Podés saltar de una alerta en una métrica directamente al log de ese error y terminar viendo la traza completa. Eso es un sistema de diagnóstico real.
El comienzo de la implementación
Entendido el valor operativo y de negocio, la pregunta es: ¿cómo arrancamos?
La realidad es que hoy en día tenemos muchas maneras de hacerlo, desde opciones base gratuitas hasta otras de pago donde tenemos todo ya preparado. Pero para darte un ejemplo, preparé un repositorio de ejemplo para que puedas ver como comenzar:
👉 Link al repo: https://github.com/PatricioPoncini/opentelemetry-express-bun
Este repositorio contiene un servicio básico que utilizando Opentelemetry permite visualizar en Grafana un dashboard pre-configurado de salud del sistema. Dentro del archivo README.md vas a poder encontrar como levantarlo localmente y algunos ejemplos de lo que te encontrarás dentro, te invito a que lo clones para que puedas explorar un poco como funciona la plataforma y que información te permite obtener.
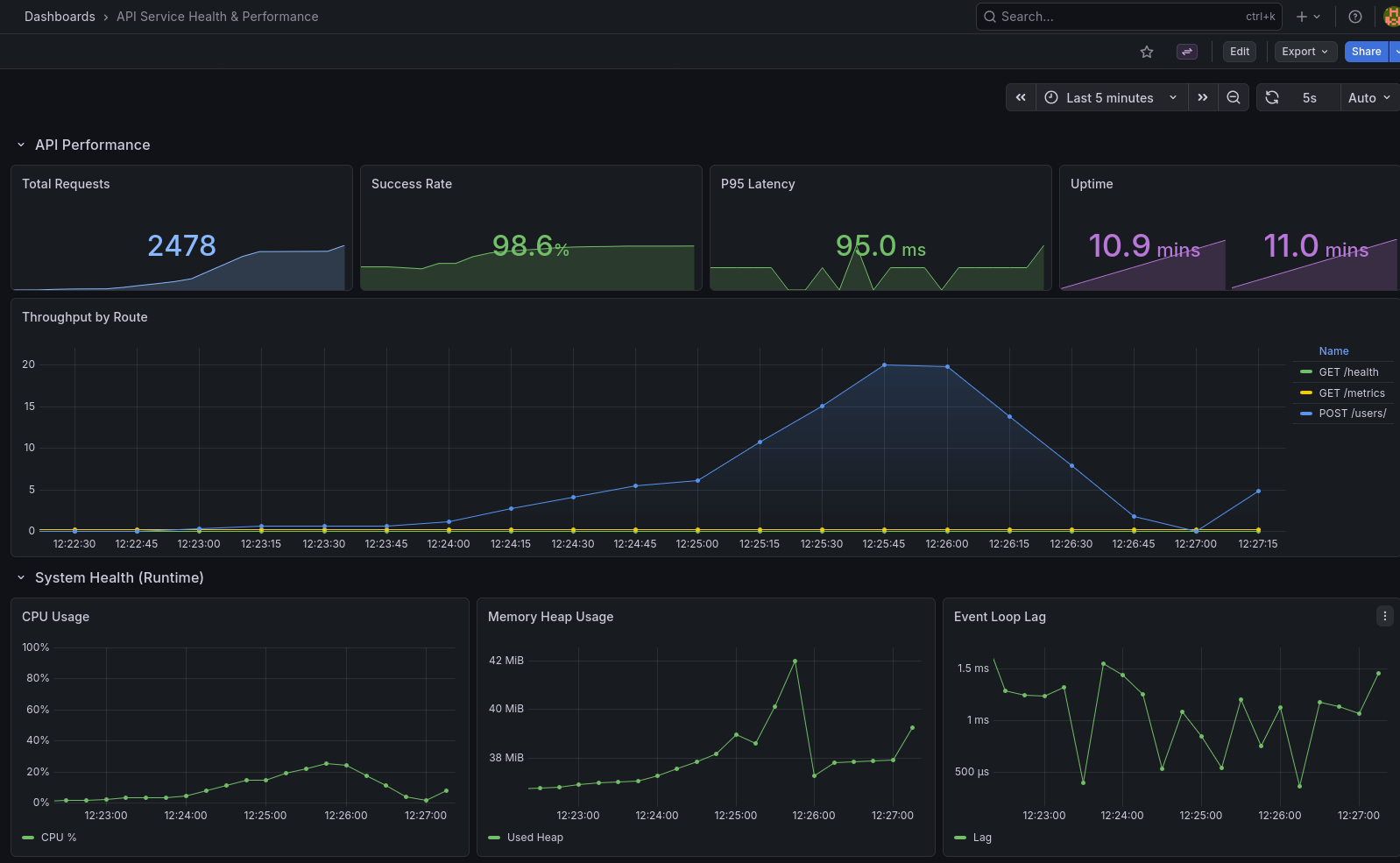
El Stack: Observabilidad unificada y estándar
Para el proyecto que te comenté anteriormente, diseñé un ecosistema de observabilidad basado en OpenTelemetry. La idea central es desacoplar la aplicación de los proveedores de monitoreo, permitiendo que el sistema sea agnóstico y escalable:
- Runtime (Bun): Usamos Bun para aprovechar su velocidad de ejecución y soporte nativo de TypeScript.
- Métricas agregadas (Prometheus): Medimos las Golden Signals (Latencia, Tráfico, Errores y Saturación) para entender la salud global y disparar alertas antes de que el usuario note una degradación.
- Logs estructurados (Loki): Pasamos del texto plano al dato estructurado. Al centralizar logs en formato JSON, podemos realizar consultas complejas en milisegundos, filtrando por contextos específicos de la aplicación.
- Trazabilidad distribuida (Jaeger): Nos permite desglosar el tiempo de respuesta y entender exactamente qué componente (código, base de datos o servicios externos) está dificultando la experiencia del usuario.
Conclusión
Como vimos a lo largo de este post, la verdadera diferencia entre un sistema que simplemente “monitorea” y uno que es realmente “observable” no reside en la estética de sus dashboards. Reside en la capacidad de respuesta y, fundamentalmente, en la facultad de interrogar a nuestra infraestructura sobre estados que nunca previmos al momento de escribir la primera línea de código.
Como desarrolladores, nuestro trabajo no termina cuando el código compila o el test pasa en verde. Nuestro trabajo termina cuando garantizamos que el sistema es transparente y predecible.
La pregunta no es si tu sistema va a fallar (porque eventualmente lo hará), sino qué tan rápido podés entender por qué ocurrió para que no vuelva a pasar. La observabilidad no es un costo extra, es la base sobre la cual se construye software de calidad.
Si llegaste hasta acá, muchas gracias por leer 😄 ¡Nos vemos en el próximo posteo!